Joins
JOIN is a key feature in Timeplus to combine data from different sources and freshness into a new stream. Please refer to https://en.wikipedia.org/wiki/Join_(SQL) for general introduction.
Streaming and Dimension Table Join
In Timeplus, all data live in streams and the default query mode is streaming. Streaming mode focuses on the latest real-time tail data which is suitable for streaming processing. On the other hand, historical focuses on the old indexed data in the past and optimized for big batch processing like terabytes large scans. Streaming is the by default mode when a query is running against it. To query the historical data of a stream, table() function can be used.
There are typical cases that an unbounded data stream needs enrichment by connecting to a relative static dimension table. Timeplus can do this in one single engine by storing streaming data and dimension tables in it via a streaming to dimension table join.
Examples
SELECT device, vendor, cpu_usage, timestamp
FROM device_utils
INNER JOIN table(device_products_info) AS dim
ON device_utils.product_id = dim.id
In the above example, data from device_utils is a stream and data from device_products_info is historical data since it is wrapped with table() function. For every (new) row from device_utils, it is continuously joined with rows from dimension table device_products_info and enriches the streaming data with product vendor information.
Three cases are supported:
stream INNER JOIN table
INNER JOIN is the most common JOIN to return data have matching values in both side of the JOIN.
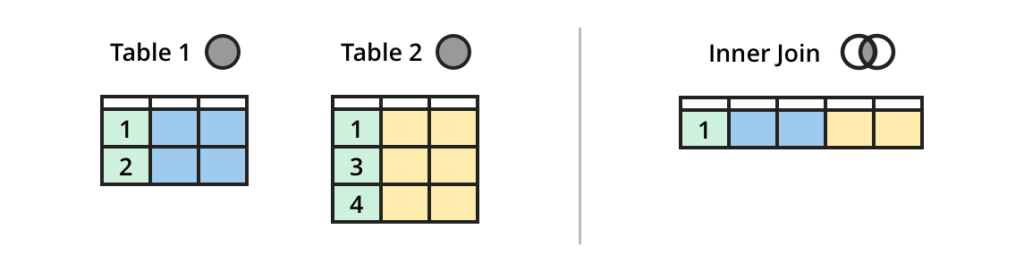
(Credit: https://dataschool.com/how-to-teach-people-sql/sql-join-types-explained-visually/)
This is also the default behaviour if you just use JOIN.
stream LEFT JOIN table
LEFT JOIN returns all rows from the left stream with matching rows in the right table. Some columns can be NULL when there is no match.
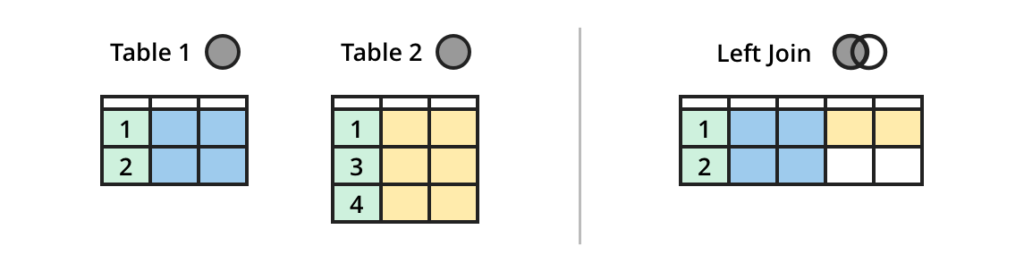
(Credit: https://dataschool.com/how-to-teach-people-sql/sql-join-types-explained-visually/)
stream OUTER JOIN table
OUTER JOIN combines the columns and rows from all tables and includes NULL when there is no match.
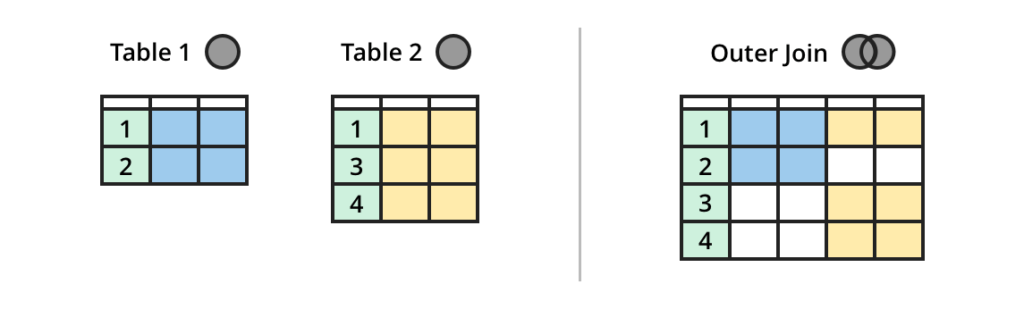
(Credit: https://dataschool.com/how-to-teach-people-sql/sql-join-types-explained-visually/)
Stream to Stream Join
In some cases, the real-time data flows to multiple data streams. For example, when the ads are presented to the end users, and when the users click the ads.
Correlated searches for multiple streams
Timeplus allows you to do correlated searches for multiple data streams. For example, you can check the average time when the user clicks the ad after it is presented.
SELECT .. FROM stream1
INNER JOIN stream2
ON stream1.id=stream2.id AND date_diff_within(1m)
WHERE ..
Self join
You can also join a stream to itself. A typical use case is to check whether there is a certain pattern for the data in the same stream, for example, whether for the same credit card, within 2 minutes, there is a big purchase after a small purchase. This could be a pattern for fraud.
SELECT .. FROM stream1
INNER JOIN stream1 AS stream2
ON stream1.id=stream2.id AND date_diff_within(1m)
WHERE ..
3 types of streams
Timeplus supports 3 stream types:
- Append only stream (default)
- Versioned Stream with primary key(s) and multiple versions
- Changelog Stream with primary key(s) and CDC semantic (data can be removed, or updated with old&new value). You can also use the changelog() function to convert an append-only stream to changelog stream.
2 join types
1.INNER
(default)
(Credit: https://dataschool.com/how-to-teach-people-sql/sql-join-types-explained-visually/)
2.LEFT
(Credit: https://dataschool.com/how-to-teach-people-sql/sql-join-types-explained-visually/)
Other types of JOINS are not supported in the current version of Timeplus. If you have good use cases for them, please contact us at support@timeplus.com.
- RIGHT
- FULL or OUTER
- CROSS
4 join strictnesses
ALL(default)LATESTFor two append-only streams, if you usea INNER LATEST JOIN b on a.key=b.key, any time when the key changes on either stream, the previous join result will be canceled and a new result will be added.ASOF, provides non-exact matching capabilities. This can work well if two streams have the same id, but not with exactly the same timestamps.- range
ASOF
Supported combinations
At the high level, the JOIN syntax is
SELECT <column list>
FROM <left-stream>
[join_type] [join_strictness] JOIN <right-stream>
ON <on-clause>
[WHERE .. GROUP BY .. HAVING ... ORDER BY ...]
By default, the strictness is ALL and the join kind is INNER.
As you can imagine, there could be 24 (3 x 2 x 4) combinations. Not all of them are meaningful or performant. Please read on for the supported combinations.
append JOIN append
This may look like the most easy-to-understand scenario. You can try this type of join if you have 2 streams with incoming new data.
However, this is designed to be exploration purpose only, not recommended to for production use. Because both sides of the data streams are unbounded, it will consume more and more resources in the system. Internally there is a setting for max cached bytes to control the maximum source data it can buffer. Once the query reaches the limit, the streaming query will be aborted.
Example:
SELECT * FROM
left_append JOIN right_append
ON left_append.k = right_append.kk
range join append streams
The above join may buffer too much data, range bidirectional join tries to mitigate this problem by bucketing the stream data in time ranges and try to join the data bidirectionally in appropriate range buckets. It requires a date_diff_within clause in the join condition and the general form of the syntax is like below.
SELECT * FROM left_stream JOIN right_stream
ON left_stream.key = right_stream.key AND date_diff_within(2m)
Actually we don’t even require a timestamp for the range, any integral columns are supposed to work. For instance, AND left_stream.sequence_number < rightstream.sequence_number + 10.
version JOIN version
This is a unique feature in Timeplus. You can setup Versioned Stream with data in Kafka or other streaming sources. Assign primary key(s) and join multiple versioned stream, as if they are in OLTP. Whenever there are new updates to either side of the JOIN, new result will be emitted.
Examples:
SELECT count(*), min(i), max(i), avg(i), min(ii), max(ii), avg(ii)
FROM left_vk JOIN right_vk
ON left_vk.k = right_vk.kk
append INNER JOIN versioned
This type of join and the following types enable you to dynamic data enrichment. Dynamic data enrichment join has special semantics as well compared to traditional databases since we don’t buffer any source data for the left stream, we let it keep flowing. It is similar to stream to dimension table join, but the difference is we build a hash table for the right stream and dynamically update the hash table according to the join strictness semantics.
Example:
SELECT * FROM append JOIN versioned_kv USING(k)
append LEFT JOIN versioned
Similar to the above one, but all rows in the append-only stream will be shown, with NULL value in the columns from versioned stream, if there is no match.
Example:
SELECT * FROM append LEFT JOIN versioned_kv USING(k)
append INNER JOIN changelog
Example:
SELECT * FROM append JOIN changelog_kv USING(k)
append LEFT JOIN changelog
Example:
SELECT * FROM append LEFT JOIN changelog_kv USING(k)
append ASOF JOIN versioned
ASOF enrichment join keeps multiple versions of values for the same join key in the hash table and the values are sorted by ASOF unequal join key.
Example:
SELECT * FROM append ASOF JOIN versioned_kv
ON append.k = versioned_kv.k AND append.i <= versioned_kv.j
There is an optional setting to ask the query engine to keep the last N versions of the value for the same join key. Example:
SELECT * FROM append ASOF JOIN versioned_kv
ON append.k = versioned_kv.k AND append.i <= versioned_kv.j
SETTINGS keep_versions = 3
append LEFT ASOF JOIN versioned
Similar to the above, but not INNER.
Example:
SELECT * FROM append LEFT ASOF JOIN versioned_kv
ON append.k = versioned_kv.k AND append.i <= versioned_kv.j
append LATEST JOIN versioned
Only the latest version of value for each join key is kept. Example:
SELECT *, _tp_delta FROM append ASOF LATEST JOIN versioned_kv
ON append.k = versioned_kv.k
Then you can add some events to both streams.
| Add Data | SQL Result |
|---|---|
Add one event to append (id=100, name=apple) | (no result) |
Add one event to versioned_kv (id=100, amount=100) | 1. id=100, name=apple, amount=100, _tp_delta=1 |
Add one event to versioned_kv (id=100, amount=200) | (2 more rows) 2. id=100, name=apple, amount=100,_tp_delta=-1 3. id=100, name=apple, amount=200,_tp_delta=1 |
Add one event to append (id=100, name=appl) | (2 more rows) 4. id=100, name=apple, amount=200,_tp_delta=-1 5. id=100, name=appl, amount=200,_tp_delta=1 |
If you run an aggregation function, say count(*) with such INNER LATEST JOIN, the result will always be 1, no matter how many times the value with the same key is changed.
append LEFT LATEST JOIN versioned
Similar to the above, but not INNER.
Example:
SELECT * FROM append LEFT LATEST JOIN versioned_kv
ON append.k = versioned_kv.k